
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
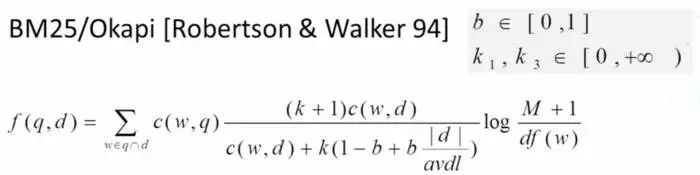
一、BM25算法原理及实现:
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
二、文本相似度-bm25算法原理及实现
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
三、文本相似度-bm25算法原理及实现
文本相似度-bm25算法原理及实现其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
四、BM25相关度打分公式
BM25算法是一种常见用来做相关度打分的公式,思路比较简单,主要就是计算一个query里面所有词和文档的相关度,然后在把分数做累加操作,而每个词的相关度分数主要还是受到tf/idf的影响。
五、相关性
对每一个搜索查询,我们很容易给每个文档定义一个“相关分数”。当用户进行搜索时,我们可以使用相关分数进行排序而不是使用文档出现时间来进行排序。这样,最相关的文档将排在第一个,无论它是多久之前创建的(当然,有的时候和文档的创建时间也是有关的)。
有很多很多种计算文字之间相关性的方法,但是我们要从最简单的、基于统计的方法说起。这种方法不需要理解语言本身,而是通过统计词语的使用、匹配和基于文档中特有词的普及率的权重等情况来决定“相关分数”。
这个算法不关心词语是名词还是动词,也不关心词语的意义。它唯一关心的是哪些是常用词,那些是稀有词。如果一个搜索语句中包括常用词和稀有词,你最好让包含稀有词的文档的评分高一些,同时降低常用词的权重。
这个算法被称为 Okapi BM25。它包含两个基本概念 词语频率(term frequency) 简称词频(“TF”) 和 文档频率倒数(inverse document frequency) 简写为(“IDF”). 把它们放到一起,被称为 “TF-IDF”,这是一种统计学测度,用来表示一个词语 (term) 在文档中有多重要。
 关注作者
关注作者 

